Transformer
Transformer
Transformer是目前最流行的深度学习架构之一,广泛应用于大语言模型(LLM)和计算机视觉等领域。
它的核心创新在于引入了自注意力机制(Self-Attention),使得模型能够更好地捕捉输入数据中的长距离依赖关系。
可视化Transformer
扩展链接-可视化Transformer
要明白Transformer 的原理,可以把 Transformer 拆解为5个关键步骤:
输入处理、特征提取、非线性变换、稳定训练 和 输出生成。
输入处理
前置知识
token
Token:是文本预处理过程中的基本单元,代表文本中的最小有意义部分。Token可以是单词、字符、词组等。
- 具体如何划分如何取决于分词器(Tokenizer)。
tokenization 分词
Tokenization:将文本转换为Token的过程。如何划分Token取决于分词器(Tokenizer)的设计。
- 分词是文本预处理的第一步,为了让计算机能够理解,还需要将分词结果转化为数字,即Token ID,模型内部一般都会内置词汇表与 Token ID 映射的编码表。
vectorization 向量化
Vectorization:向量化是将非结构化数据(如文本、图像、声音等)转换为数值向量的过程。
- 但是由于传统向量存在语义缺失、稀疏等问题,因此我们需要使用嵌入(Embedding) 来将离散的Token转换为连续的向量表示。
embedding 嵌入
Embedding:Embedding 是更高级的向量化,它将token ID转换成一个高维向量,这个向量代表了词的语义。
输入处理流程
计算机看不懂文字,只能看懂数字。
- 分词(Tokenization):将输入文本分割成Token,再将每个Token转换为对应的Token ID。
- 词嵌入(Word Embedding):将Token ID转换为一个高维向量,这个向量包含了词的语义信息。
- 位置编码(Positional Encoding):因为 Transformer 是一次性并行读取所有词,会打乱顺序,
因此需要引入“位置向量”(利用正弦和余弦函数生成)来表示其位置信息。
特征提取
前置知识
Self-Attention 自注意力机制
让模型能够判断,对当前 token 来说,输入序列中的哪些 token 是重要的,从而更好地理解上下文关系。
在实现上,它通过三个向量矩阵来运算:Q (Query)、K (Key)、V (Value)。
- Q (查询):代表“我想找什么信息”。
- K (键):代表“我拥有什么信息”。
- V (值):代表“我的实际内容”。
运算过程(缩放点积注意力):在下面多头自注意力一起讲解。
多头自注意力
(Multi-head Self Attention)
为了让模型理解得更全面,Transformer 不是只算一次注意力,而是把 Q、K、V 切分成多份(比如 8 个头),并行计算。
每个头的运算过程
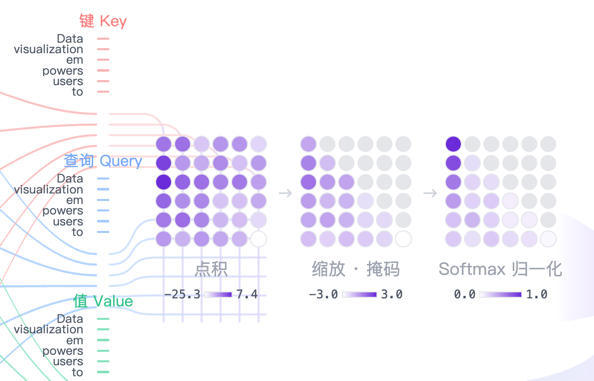
- 打分:用当前词的 Q 去和句子里所有词的 K 做点积运算。这就像是在计算“我”和“其他词”的相关性得分。
- 缩放与归一化:将得分除以一个缩放因子(通常是 K 的维度的平方根,这是防止数值过大导致梯度消失),
然后通过 softmax 函数,将得分转换为0 到 1 之间的概率(权重)。 - 加权求和:用算出来的权重去乘以 V
- 直观理解:如果“它”和“动物”的相关性权重很高,那么在计算“它”的表示时,就会把“动物”的信息(V)大量融合进来。
- 有的头可能关注语法结构(主谓宾);
- 有的头关注指代关系(它=动物);
- 有的头关注语义关联。
最后把这 8 个结果拼接起来,就得到了更丰富的信息表示。
非线性变换
前馈神经网络
在注意力层输出后,Transformer 还会通过一个前馈神经网络(Feed-Forward Neural Network,FFN),细化token的表示。
- 这个网络通常包含两个线性层和一个非线性激活函数(如ReLU)。
- 其过程为 线性层 -> 激活函数 -> 线性层。
- 这个步骤的作用是增加模型的表达能力,让它能够捕捉更复杂的模式和关系。
稳定训练-了解
残差连接和层归一化
为了让模型更容易训练,Transformer 引入了残差连接(Residual Connection)和层归一化(Layer Normalization)。
输出生成
- 当完成前面步骤后,模型会输出一个巨大的向量(长度等于词表大小,比如 50,000),里面的每个数字代表词表中对应词的“得分”(Logits)。
- 此时还没有概率,只是原始分数。
- Temperature 介入: 它会把线性层输出的这些“得分”除以温度值 T。
什么是 Temperature
- Temperature 是一个调节生成文本多样性的参数。它通过调整 Logits 的分布来控制生成文本的随机程度。
- 公式:
P(i) = exp(logit_i / T) / sum(exp(logit_j / T)),其中 T 是 Temperature。 - 当 T < 1 时,模型更倾向于选择得分较高的词,生成更确定性的文本;当 T > 1 时,模型会增加选择得分较低词的概率,生成更多样化的文本。
temperature 的作用
- temperature 越低,生成的文本越稳定
- temperature 越高,生成的文本越多样化
- Softmax 函数:将经过温度调整后的分数转化为概率(0 到 1 之间,总和为 1)。
- 最后根据这些概率,模型会选择一个词作为输出,
选择范围的策略
- 只在概率最高的 k 个词里随机选(Top-k)
- 只在累积概率达到 p 的词集合里随机选(Top-p)
- 直接选概率最高的那个词(Greedy)