神经网络
神经网络
神经网络就是模仿人脑神经元的结构,其典型应用就是Transformer架构。
神经网络的基本结构
神经网络由输入层、隐藏层和输出层组成。
每一层由多个神经元组成,神经元之间通过权重连接。
输入层接收外部数据,隐藏层进行特征提取和变换,输出层产生最终结果。
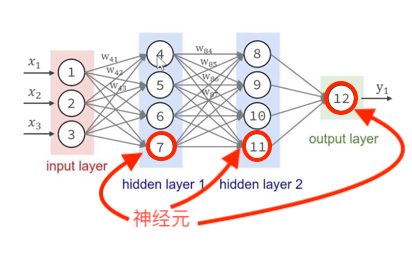
- 输入层:接收数据。
- 隐藏层:进行特征提取和变换。可以有多层。
- 输出层:产生最终结果。
神经网络的计算过程
总结
根据下面计算过程可以得出,神经网络本质是:
线性变换(加权求和 + 偏置) + 非线性变换(激活函数)。
输入层->隐藏层
- 输入向量:输入层本身不进行计算,它只是把数据向量 x 传递给隐藏层。
- 隐藏层的计算:隐藏层的每个神经元会接收输入,进行加权求和,加上偏置,然后使用激活函数计算。
(线性变换:加权求和 + 偏置)
其中, 是输入层到隐藏层的权重, 是偏置, 是激活函数。
激活函数
激活函数:引入非线性,使神经网络能够学习复杂的模式。常见的激活函数有ReLU、Sigmoid、Tanh等。
隐藏层->输出层
- 隐藏层的输出:隐藏层的输出 作为输入传递给输出层。
- 输出层的计算:输出层的每个神经元同样进行加权求和和激活函数计算,产生最终输出。
(线性变换:加权求和 + 偏置)
其中, 是隐藏层到输出层的权重, 是偏置, 是输出层的激活函数。
神经网络的训练
大模型的训练
大模型的训练和神经网络训练是不同的,大模型是宏观的训练过程,神经网络训练是微观的训练过程。
训练过程为:
- 预训练(Pre-training)
- 微调(Fine-tuning)
了解了神经网络的计算流程后,我们可以发现,神经网络的训练就是调整 权重和偏置 ,使得输出结果尽可能接近真实标签。
训练过程
初始化
训练开始前,网络对所有输入数据一无所知。
因此,我们会将所有神经元之间的连接权重(Weights)和偏置(Biases)设置为随机的小数值。
这就好比给大脑的神经元连接一个随机的初始状态。
前向传播
我们将一批训练数据输入网络。
数据会从输入层开始,逐层经过隐藏层的计算(加权求和与激活函数),最终到达输出层,产生一个预测结果。
计算损失
我们将网络的 预测结果 与数据的 真实标签 进行比较。
- 这个比较通过一个损失函数(Loss Function)来完成。损失函数会计算出一个数值,即损失值(Loss)。
- 这个值越大,代表预测结果与真实情况相差越远;值越小,代表预测得越准。训练的目标就是让这个损失值尽可能小。
损失函数
损失函数:衡量模型预测结果与真实标签之间的差距。常见的损失函数有均方误差(MSE)和交叉熵损失等。
反向传播
根据损失值,计算每个权重和偏置的梯度。
- 反向传播算法会从输出层开始,利用微积分中的链式法则,将误差沿着网络连接反向逐层传播回输入层。
- 在这个过程中,它会计算出每个权重对总误差的“贡献度”,这个贡献度在数学上被称为梯度(Gradient)
- 梯度告诉我们,如果想减小误差,每个 权重 和 偏置 应该朝哪个方向调整,以及调整的幅度有多大。
参数更新
使用优化算法(如梯度下降),根据上一步计算出的梯度来更新 权重和偏置,使损失值最小化。
- 更新的原则很简单:沿着梯度的反方向去调整权重。因为梯度指向的是误差增长最快的方向,所以反方向就是误差减小最快的方向。
- 调整的步长由一个叫做学习率(Learning Rate)的超参数控制。学习率太大可能导致训练不稳定,太小则训练速度太慢。
- 更新公式通常是:,其中 是学习率(Learning Rate),它控制着每次更新的步长。
重复
重复以上步骤,直到模型收敛或达到预设的训练轮数。
训练的目标
训练的目标是找到一组权重和偏置,使得神经网络在训练数据上的输出结果尽可能接近真实标签,从而使模型具有良好的泛化能力,在未见过的数据上也能表现良好。
- 简单来说就是让损失函数的值尽可能小。
补充-训练模型的关键概念
周期 (Epoch)
一个周期指的是网络将整个训练数据集完整地“学习”了一遍。由于数据量通常很大,一个周期内会包含多次参数更新。一个模型通常需要训练几十个甚至上百个周期才能收敛。
批次 (Batch)
我们不会一次性把所有数据都喂给网络,而是将数据分成一个个小份,每一份就叫做一个批次。
例如,有60,000张训练图片,我们可以设置批次大小为32,那么一个周期内就需要进行 60000 / 32 ≈ 1875 次迭代(即参数更新)。使用批次可以提高训练效率,并帮助模型更好地泛化。
优化器 (Optimizer)
优化器是用来更新神经网络权重和偏置的算法(参数更新)。常见的优化器有随机梯度下降(SGD)、Adam、RMSprop等。不同的优化器在更新参数时采用不同的策略,可能会影响训练速度和模型性能。